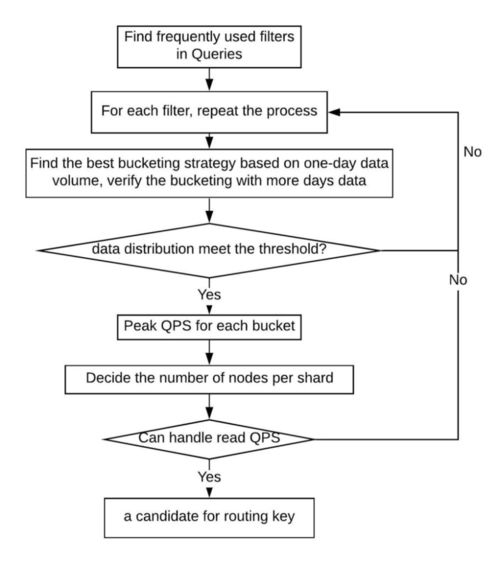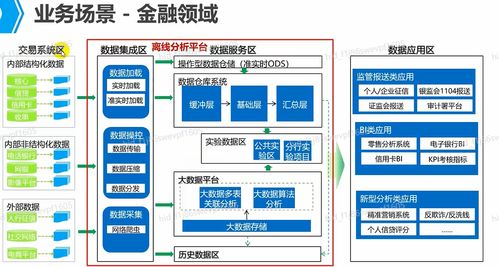
在當今數據驅動的商業環境中,離線數據處理作為大數據生態系統的基石,承擔著海量歷史數據的清洗、整合、轉換與深度分析的重任。它通常指對非實時、批量的數據進行處理,適用于對時效性要求相對寬松,但對準確性、完整性和計算復雜度有較高要求的場景。一個成熟的數據離線處理場景化解決方案,必須構建一個強大、靈活且可擴展的數據處理和存儲支持服務體系。
一、核心場景與業務挑戰
典型的離線處理場景包括:
- 歷史數據報表與分析:生成每日、每周或每月的業務報表,進行趨勢分析和業績復盤。
- 數據倉庫與數據湖構建:將分散在各個業務系統的數據經過ETL(抽取、轉換、加載)過程,整合到統一的數據倉庫或數據湖中,形成企業級數據資產。
- 機器學習模型訓練:為復雜的AI模型提供大規模、高質量的訓練數據集,進行特征工程和模型迭代。
- 用戶行為分析與畫像:對積累的用戶日志進行批量處理,構建精準的用戶畫像,用于個性化推薦和營銷。
這些場景面臨的共同挑戰包括:數據來源多樣、格式不一、質量參差;處理任務繁重,計算資源消耗大;流程復雜,依賴關系管理困難;以及需要確保處理結果的準確性與一致性。
二、分層解耦的解決方案架構
一個有效的場景化解決方案通常采用分層架構,實現關注點分離:
- 數據采集與接入層:
- 支持服務:提供多樣化的數據接入工具,支持從數據庫(通過增量/全量同步)、日志文件、消息隊列、FTP/SFTP服務器以及API接口等穩定地抽取數據。
- 關鍵能力:斷點續傳、數據校驗、臟數據隔離與告警。
- 數據處理與計算層(核心):
- 批處理引擎:采用如Apache Spark、Flink(批處理模式)、Hive、MapReduce等計算框架,提供強大的分布式計算能力。解決方案需根據場景(如復雜SQL分析、迭代計算、圖計算)選擇合適的引擎。
- 工作流調度與服務:集成如Apache Airflow、DolphinScheduler、Azkaban等工作流調度系統,將分散的數據處理任務編排成有序、可視化的DAG(有向無環圖),實現任務依賴管理、定時觸發、失敗重試與監控告警。
- 數據質量與服務治理:內置數據質量校驗規則(如完整性、唯一性、一致性檢查),并提供元數據管理、數據血緣追蹤服務,確保數據處理過程可信、可追溯。
- 數據存儲與服務層:
- 分級存儲支持:根據數據的訪問頻率和成本要求,設計分層的存儲策略。
- 熱存儲:用于存放頻繁訪問的中間或結果數據,如HDFS、高性能對象存儲。
- 溫/冷存儲:用于歸檔歷史數據,如低成本對象存儲或磁帶庫,通過生命周期管理策略自動遷移。
- 多樣化存儲格式支持:針對不同分析場景,支持列式存儲(如Parquet、ORC,適用于分析型查詢)、行式存儲以及混合存儲格式,以優化I/O效率和查詢性能。
- 統一數據服務:通過數據API、數據市場或即席查詢工具(如Presto/Trino),將處理后的標準化數據安全、便捷地提供給下游的業務系統、數據分析師和應用程序,實現數據價值交付。
- 運維監控與安全管理層:
- 全鏈路監控:對數據流水線的健康狀態、任務執行時長、資源利用率(CPU、內存、磁盤I/O)進行全方位監控和可視化展示。
- 資源管理與彈性伸縮:基于YARN、Kubernetes等資源管理器,實現計算資源的池化與按需彈性分配,提高集群利用率,應對峰值任務。
- 安全與權限:提供貫穿數據采集、處理、存儲和訪問全流程的權限控制、數據加密(靜態和傳輸中)及審計日志服務,保障數據安全合規。
三、構建支持服務的關鍵考量
實施該解決方案時,其支持服務的構建需聚焦以下幾點:
- 場景化封裝與模板化:針對常見的業務場景(如日志分析、ETL任務、用戶畫像),將最佳實踐封裝成可復用的任務模板或組件,降低使用門檻,提升開發效率。
- 彈性與成本優化:利用云原生或混合云架構,實現計算存儲分離和資源的彈性伸縮。通過Spot實例、自動啟停集群、數據壓縮與冷熱分離等手段,有效控制總體擁有成本(TCO)。
- 可觀測性與智能化運維:不僅監控任務成敗,更深入洞察性能瓶頸。結合機器學習,實現異常任務自動檢測、根因分析建議乃至智能調優(如動態資源分配、Spark參數優化)。
- 開放與集成:解決方案應具備良好的開放性,能夠與企業現有的身份認證系統(如LDAP/AD)、項目管理工具、通知系統(郵件、釘釘、企業微信)及云平臺服務無縫集成。
###
數據離線處理場景化解決方案的本質,是將復雜的技術棧整合為一套以業務場景為導向、以數據流為核心的服務體系。強大的數據處理和存儲支持服務是這一體系的“中樞神經”和“骨骼肌肉”,它確保了海量數據能夠被高效、可靠、經濟地轉化為可用的信息資產。企業通過構建或引入這樣一套體系,不僅能應對當前的數據處理需求,更能為未來探索實時分析、數據智能等更高級別的應用奠定堅實的數據基礎。