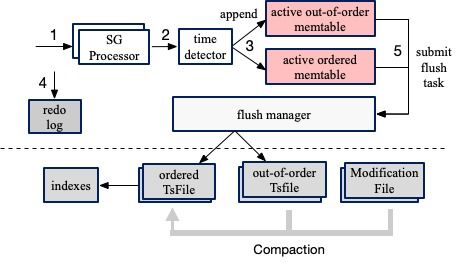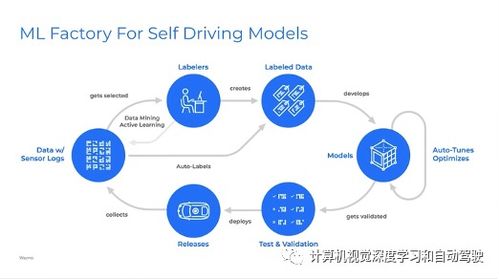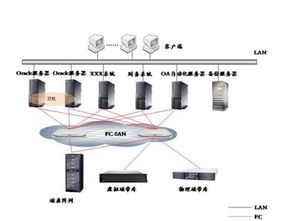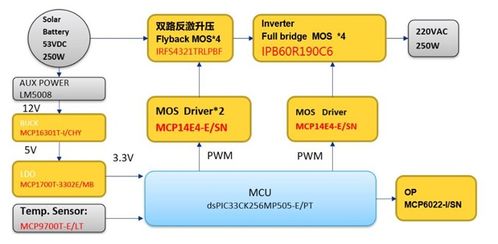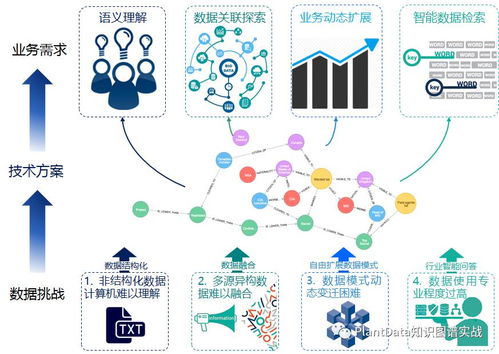
隨著人工智能與大數(shù)據(jù)技術的飛速發(fā)展,知識圖譜作為連接海量異構數(shù)據(jù)、構建機器認知能力的核心技術,已廣泛應用于智能搜索、推薦系統(tǒng)、金融風控、智慧醫(yī)療等領域。構建與維護一個大規(guī)模、高質(zhì)量的知識圖譜,其背后數(shù)據(jù)存儲系統(tǒng)的設計與選型至關重要。本文將聚焦于大規(guī)模知識圖譜的數(shù)據(jù)處理流程與存儲支持服務,解析其中的核心挑戰(zhàn)與實踐方案。
一、 大規(guī)模知識圖譜數(shù)據(jù)的特點與存儲挑戰(zhàn)
大規(guī)模知識圖譜數(shù)據(jù)通常具有以下特點:
- 數(shù)據(jù)規(guī)模龐大(Volume):涉及數(shù)十億甚至萬億級別的實體與關系。
- 結構復雜多樣(Variety):包含結構化的RDF三元組、半結構化的JSON/XML屬性,以及非結構化的文本描述、圖像等。
- 高度關聯(lián)性(Relation):實體之間通過多種關系深度連接,形成復雜的網(wǎng)絡拓撲。
- 動態(tài)演變(Velocity):知識需要持續(xù)更新,支持增量和實時數(shù)據(jù)的接入。
這些特點對存儲系統(tǒng)提出了嚴峻挑戰(zhàn):如何高效存儲海量三元組、如何支持復雜的圖查詢(如多跳查詢、路徑查詢)、如何保證高并發(fā)讀寫性能、以及如何實現(xiàn)水平擴展。
二、 數(shù)據(jù)處理流程:從原始數(shù)據(jù)到知識存儲
大規(guī)模知識圖譜的構建始于數(shù)據(jù)處理,這是一個多階段的流水線:
- 數(shù)據(jù)采集與接入:從異構數(shù)據(jù)源(數(shù)據(jù)庫、文檔、API、網(wǎng)頁)收集原始數(shù)據(jù)。存儲支持服務需提供靈活的數(shù)據(jù)接入接口(如Kafka消息隊列),緩沖高速流入的數(shù)據(jù)。
- 知識抽取與融合:通過自然語言處理(NLP)技術從非結構化文本中抽取實體、關系、屬性,并與現(xiàn)有知識進行對齊、消歧、融合。此階段產(chǎn)生結構化的RDF三元組或?qū)傩詧D數(shù)據(jù)。
- 數(shù)據(jù)清洗與質(zhì)量管控:對抽取的知識進行一致性校驗、沖突解決與補全。存儲系統(tǒng)在此階段可提供版本管理或事務支持,確保數(shù)據(jù)質(zhì)量。
- 存儲建模與導入:將清洗后的數(shù)據(jù)轉(zhuǎn)換為目標存儲模型(如屬性圖模型或RDF模型),并通過批量導入工具高效載入存儲引擎。
三、 存儲支持服務的核心架構與選型
針對上述挑戰(zhàn),現(xiàn)代知識圖譜存儲支持服務通常采用分層或混合架構。
1. 核心存儲引擎選型
- 原生圖數(shù)據(jù)庫(如Neo4j, JanusGraph, Nebula Graph):以“圖優(yōu)先”方式存儲,將關系作為一等公民,在深度關聯(lián)查詢(如最短路徑、社區(qū)發(fā)現(xiàn))上性能卓越。適用于關系復雜、查詢模式多變的場景。
- RDF三元組存儲(如Apache Jena Fuseki, Virtuoso):專門為RDF標準設計,支持SPARQL查詢,語義推理能力強。常見于需要嚴格遵循語義網(wǎng)標準的領域。
- 分布式鍵值/列式存儲(如HBase, Cassandra)與圖計算層結合:利用其強大的水平擴展能力存儲底層數(shù)據(jù),通過上層圖計算引擎(如Apache TinkerPop)提供圖查詢接口。適合數(shù)據(jù)量極其龐大、需要線性擴展的場景。
2. 混合存儲架構實踐
單一存儲引擎往往難以滿足所有需求,因此混合架構成為趨勢:
- “熱-溫-冷”數(shù)據(jù)分層存儲:將高頻訪問的“熱”數(shù)據(jù)(如核心實體關系)存放在內(nèi)存或SSD圖數(shù)據(jù)庫中,保證低延遲查詢;將“溫”數(shù)據(jù)(歷史關系、詳細屬性)存放在分布式NoSQL數(shù)據(jù)庫中;將歸檔的“冷”數(shù)據(jù)存放在對象存儲(如S3)中。通過統(tǒng)一查詢層對應用透明。
- 圖數(shù)據(jù)庫與搜索引擎(如Elasticsearch)結合:圖數(shù)據(jù)庫處理關聯(lián)查詢,搜索引擎處理全文檢索和復雜屬性過濾,二者通過同步機制保持數(shù)據(jù)一致,優(yōu)勢互補。
- OLTP與OLAP分離:在線事務處理(OLTP)圖數(shù)據(jù)庫負責實時增刪改查,而將數(shù)據(jù)定期同步到數(shù)據(jù)倉庫或圖計算平臺(如Spark GraphX)進行離線分析、挖掘和批量計算。
四、 實戰(zhàn)考量與優(yōu)化策略
- 數(shù)據(jù)建模:根據(jù)查詢模式設計圖模型(如鄰接表、屬性圖),合理使用索引(如對實體類型、常用屬性建立索引),避免超級節(jié)點(高度數(shù)節(jié)點)的出現(xiàn)。
- 分區(qū)與分片:對于分布式存儲,需設計有效的圖分區(qū)策略(如基于邊切割或基于節(jié)點哈希),以最小化跨分區(qū)查詢,提升性能。
- 緩存策略:利用Redis等緩存高頻查詢結果或熱門子圖,顯著減少后端存儲壓力。
- 一致性、可用性與擴展性權衡:根據(jù)業(yè)務需求在強一致性與最終一致性之間做出選擇,設計平滑的集群擴容方案。
- 監(jiān)控與運維:建立完善的監(jiān)控體系,跟蹤存儲性能指標(如查詢延遲、吞吐量)、數(shù)據(jù)增長趨勢,實現(xiàn)自動化備份與恢復。
五、 未來展望
大規(guī)模知識圖譜存儲將朝著更智能、更融合的方向發(fā)展:云原生圖數(shù)據(jù)庫服務(Graph DBaaS)將簡化運維;存儲與計算一體化架構將進一步提升實時分析能力;結合新型硬件(如PMem、GPU)的圖加速技術也將成為研究熱點。
###
構建大規(guī)模知識圖譜的存儲系統(tǒng)是一項復雜的系統(tǒng)工程,沒有“銀彈”。成功的實踐源于對業(yè)務場景、數(shù)據(jù)特性與查詢模式的深刻理解,以及對不同存儲技術棧的巧妙組合與優(yōu)化。通過構建健壯的數(shù)據(jù)處理流水線與靈活高效的存儲支持服務,方能釋放出海量知識背后的巨大價值,為上層智能應用奠定堅實的數(shù)據(jù)基石。